
How many of you faced a META outage last week? As they have a proper incident response system the issue got resolved within 2 Hours. They have identified the root cause as a Technical issue.
Let's explore a bit on the timeline of the incident:
According to The downdetector.com, the peak of the outage was around 8 PM IST and Facebook has reported it as disruption around 8:47 PM.
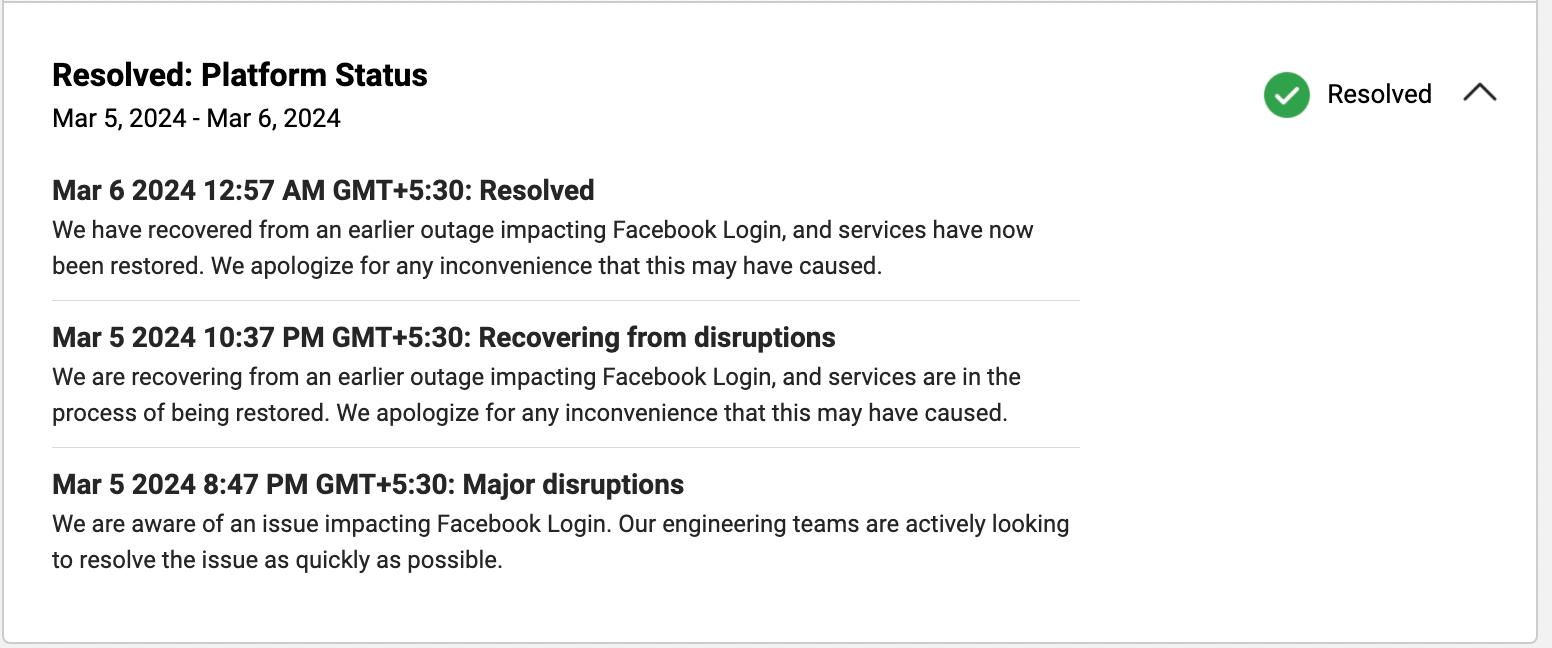
As they reported it as an outage within 40 minutes, they might have identified the issues maybe before that. If we calculate the loss, Shortly after disruptions began being reported, Meta’s share price dropped by 1.5 %.
In the modern world, time is money and it's very critical to run a product without downtime and incidents. The longer it takes to detect and respond to an incident, the greater the potential damage it can inflict.
If your application is facing issues it directly impacts the revenue and you may lose the customer's trust. This is because customers expect reliable and consistent service from software applications. If they experience delays or issues, they may seek alternatives, causing you to lose revenue and market share.
This is where Mean Time to Detect (MTTD) plays a vital role. Understanding and optimizing MTTD is crucial for an effective incident response system and minimizing the impact of cyber threats.
What is MTTD?
MTTD or Mean Time to Detect is an important metric that measures the average time taken to identify an incident. It is a key performance indicator for IT incident management which can provide insights into an organisation's readiness and efficiency in spotting and responding to potential threats.
The formula for MTTD is the sum of all incident detection times for a given technician, team, or time period divided by the total number of incidents.
Let's say A company 'XYZ' in August experienced four incidents in their application and they were able to detect the issues in the following manner
| Start time | Detected time | Elapsed |
| 1:00 AM | 2:00 AM | 3600 s |
| 2:00 AM | 2:30 AM | 1800 s |
| 3:00 AM | 3:15 AM | 900 s |
| 8:00 PM | 9:00 PM | 3600 s |
The MTTD can be calculated by dividing the summation of elapsed by the total number of incidents
MTTD = (3600 + 1800 + 900 + 3600) /4
which equals 2475s or 41.25 minutes, and is not considered to be good MTTD unless it's reasonable
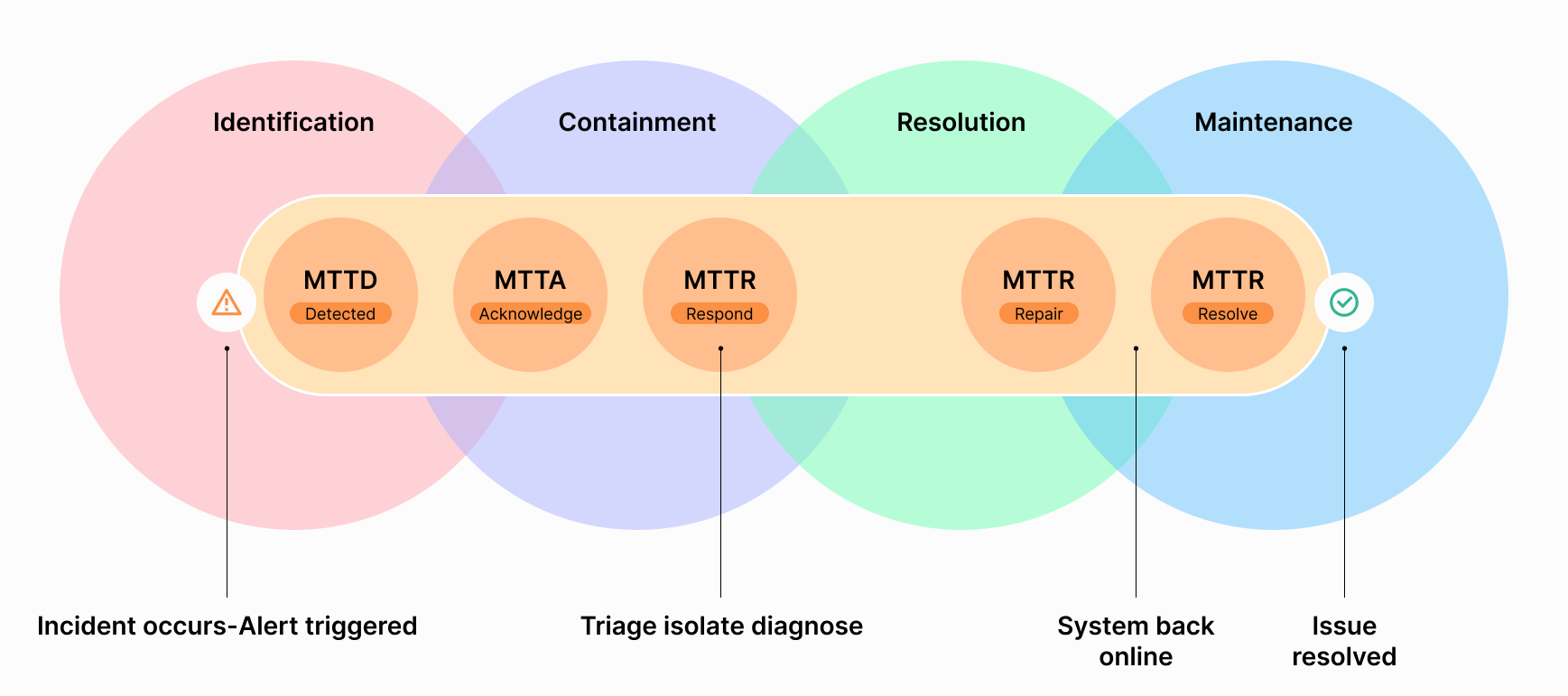
What's a good MTTD?
A low MTTD represents a robust and efficient incident management system, while a high MTTD suggests a weak monitoring system which leads to delayed incident discovery and incident escalation. A Higher MTTD may cause a loss of trust among customers and also represents Higher downtime, which affects availability and leads to unhappy customers. In order to gain the trust of your customers you should reduce the MTTD which speeds up the process of incident response.
In general, we can say you should be able to detect the problems in your system before the customer should and Regardless of the type of security breach that arises, MTTD should be a time close to zero
How to Improve MTTD?
The MTTD can be improved by the following points:
Proactive monitoring systems
Organizations should implement robust monitoring and logging systems that will analyze network traffic, system logs, and user activities for any signs of suspicious behavior or anomalies. If anything goes wrong the first places to check for evidence are these systems. The lack of these systems may result in an increase in MTTD and threats may go unnoticed for a longer period.
Alerting systems
Monitoring systems may help in forensic analysis but to be proactive we should create alerts that should check every aspect of the applications. While creating the alerts always add priorities and this helps focus attention on the most critical alerts, reducing the time it takes to detect and respond to potential incidents.
Automation
To detect incidents faster and respond efficiently, companies can use automation and orchestration tools. These tools can handle repetitive tasks such as log analysis, threat correlation, and initial investigation. By automating routine tasks, security analysts can focus on more complex threats and minimize the time it takes to detect incidents. This can improve overall incident response efficiency.
Skill and Expertise
Well-trained security professionals add value to the incident response system. Investing in ongoing training programs can enhance the capabilities of security teams, enabling them to detect and mitigate threats more effectively and fast.
Threat Intelligence Integration
Integrating threat intelligence feeds into your security infrastructure is essential for guarding your digital assets. By doing so, you can gain valuable insights into emerging threats and attack patterns, which can help you stay one step ahead of malicious activities.
Well-Documented Incident Response Process
In every organization, The incident response system and process should be documented properly because if it's available it will be helpful for the security personnel, who are handling the process as a reference. Documenting the previous incidents is also recommended as they can be used as a reference in future incidents.
For references please read Atlassian's post-incident review
For the conclusion part, I Would say that reducing the MTTD is crucial for organizations to save money, run smoother, and stay competitive. Achieving this requires a strategic, proactive approach that must be monitored and reviewed regularly to ensure it's working.
We have discussed various ways by which we could reduce the MTTD. Earlier detection of incidents plays a vital role, but detection alone doesn't solve the problem, it should be proactively fixed.
